
EMRとは
Elastic MapReduceの略であり、ビッグデータの処理を提供する。
そもそもMapReduceとは、Googleが開発したビッグデータの分散処理ビッグデータの分析を手軽に効率よく行うプログラミングモデル。
MapReduceを実装するにあたってはApache HadoopやApache Sparkなどのフレームワークが必要とされる。ただ、かなりの専門知識が要求される。
また、ビッグデータ処理の複雑さに対して複数のノードを連携して並列処理を行うには大変な労力が必要であり、データ量などに応じたリソースの調整も難しい。
そういった問題を解決出来るサービス。
アーキテクチャ

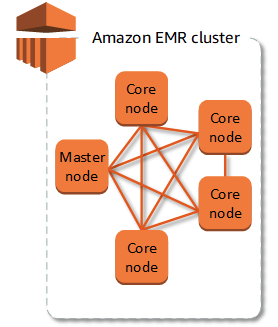
前提として、インスタンスの実態はEC2。
クラスタ内にはノードタイプ(ロール)があり、各ノードタイプに対して必要なソフトウェアがインストールされている。ノードタイプは以下
マスターノード
クラスタの管理と制御を担当。各ノードを監視し、リソースの再分配やエラーハンドリングを行う。
1台か3台か選択可能。稼働中の台数変更は不可。障害時は自動フェールオーバー。
コアノード
タスクの処理とHDFS (Hadoop Distributed File System) にデータを保持。
タスクノード(オプション)
タスク処理のみ。スケーリングに利用。
スケールインの注意事項
コアノードはHDFSにデータを保持する為、デコミッション(ノードを安全にクラスタから削除するプロセス)してからスケールインする必要がある。
フリートインスタンス
コアノードかタスクノードに於いて、インスタンスタイプを複数組み合わせる事が出来る。
EMRFS
S3を拡張的なHDFSとして使用できる。一時的なデータ処理や作業中のデータはHDFSを使用し、長期的なデータ保管や複数のクラスタやジョブ間で共有する必要があるデータにはEMRFS(つまりS3)を利用する。
EMRFS整合性のあるビュー
S3との読み書きを行うが、S3は結果整合性モデル。
この機能で整合性が保証される。メタデータはDynamoDBに保持される。
監視Glueデータカタログ
・外部のメタストアとして指定可能。
・永続的なメタストア、異なるクラスター、サービス、アプリ、AWSアカウント、で共有するメタストアが必要な場合に有効
EMRノートブック
・Jupyterと言う開発環境をベースにしたインタラクティブに分析するノートブック
※インタラクティブとは入力に対して直ぐに結果が表示される様なもん
・記述内容はクラスターとは別のS3に保存
Hadoopエコシステムの種類
Hadoopエコシステムは多くのプロジェクトやツールから成っており、それぞれがビッグデータの特定の問題を解決するための機能を持っている。特に代表的なものを挙げると次の通り。
- Hadoop Distributed File System (HDFS): Hadoopの中心となる分散ファイルシステムで、大量のデータを安全かつ効率的に保存、処理することができる。
- MapReduce: 大量のデータセットを並行処理するためのプログラミングモデル。データを”マップ”(分割・個別処理)し、その後”リデュース”(結果の集約)する。
- Apache Hive: SQL風のクエリ言語(HiveQL)を提供し、Hadoop上でデータのクエリと分析を容易にする。主にデータウェアハウジングの目的で使用される。
- Apache HBase: Hadoop上でリアルタイムの読み書きを実行するための分散データベース。大量のデータを高速に処理することが可能。
- Apache Spark: 高速なデータ処理を目指した一般的な処理エンジン。インメモリ処理により、MapReduceよりも高速な性能を発揮。機械学習やグラフ処理、ストリーム処理などにも対応。
- Apache Kafka: 大量のリアルタイムデータを高速に処理するストリーミングプラットフォーム。メッセージキューとしても機能し、大規模なデータパイプラインの構築によく使われる。
Apache Sparkのライブラリ
- Spark SQL:構造化および半構造化データを処理するためのSparkのモジュール。
SQL(構造化クエリ言語)とデータフレームAPIを提供。あらゆる種類のデータソースに対してSQLクエリを実行可能となる。 - Spark Streaming:リアルタイムのデータストリームを処理するためのライブラリ。
ライブデータの連続したストリームを小さなバッチに分割して、SparkのコアAPIを利用して処理を行う。これにより、ライブデータをリアルタイムで処理することができる。 - MLlib(Machine Learning Library):機械学習の機能を提供するライブラリで、多くの機械学習アルゴリズムを提供。
- GraphX:グラフと並列グラフ計算のためのAPIを提供するSparkのライブラリ。グラフデータを扱うための多くのアルゴリズムを提供しており、データをグラフとして表現し、グラフ上で計算を行うことができる。

